Hexapod RL
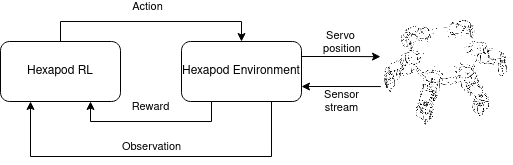
Die Hexapod Struktur wurde vom Vorjahr übernommen und ist auf zwei Geräte aufgeteilt. Auf einem Rechner läuft das Reinforcement-Learning und ein Hexapod-Environment, welches den echten Hexapod fernsteuert.
Action
Der Aktionsraum des Hexapods besteht aus 18 Werten zwischen -1,0 und 1,0. Diese stellen die negative oder positive Bewegung der 18 Servos des Hexapods dar.

Environment
Das Environment für diese Anwendung ist die HexapodEnv Klasse. Der RL-Agent kann einen Schritt/eine Aktion an das Environment senden. Dieses berechnet die neuen Servopositionen aus der Aktion unter Berücksichtigung der Einschränkungen der Beinbewegungen, z. B. „nicht selbst Stechen“. Die neuen Servopositionen werden an den Hexapod gesendet. Die Beobachtung und Belohnung werden berechnet, nachdem der echte Hexapod die Servobewegung ausgeführt hat.
Observation
Die Observation besteht aus einem Array mit folgenden Inhalt:
- Servopositionen (berechnet)
- Beschleunigungsmessung (x,y,z)
- Gyroskop (x,y,z)
- Orientierung (roll, pitch, yaw)
- Höhe (über Boden)
- Lidar (Abstand rundherum)
Reward
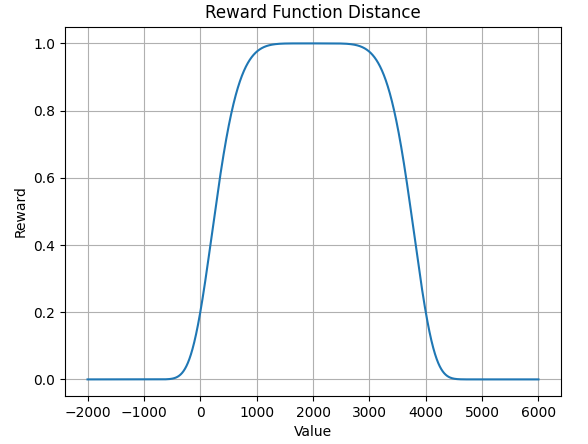
Unsere Vorgänger nutzten bereits eine parametrisierbare Exponentialfunktionen, um die Belohnung aus Höhe und Neigung zu berechnen. Diesen Ansatz haben auch wir bei der Reward-Funktion des Lidar-Sensors verfolgt. Der Plot der Reward-Funktion zeigt, dass der höchste Reward bei dem Wert 2000 (20cm) ausgegeben wird.
Durch diese Reward-Funktion versucht der Hexapod die Distanz zum nächstgelegenen Objekt auf 20 cm zu bringen. Der Reward fällt ab, sobald er sich von dem nächstgelegenen Objekt entfernt.
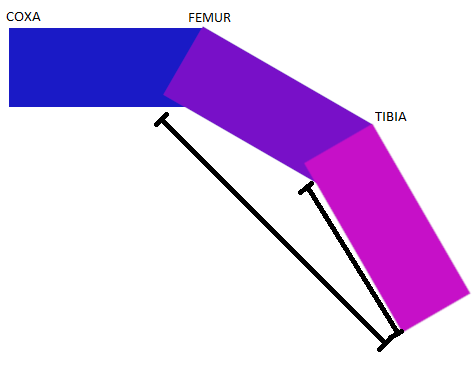
Hebelarm
Leider stellte sich heraus, dass die Servos des Hexapods, nicht stark genug sind, um das Gewicht des gesamten Körpers zu tragen.
Dieses Problem entsteht durch einen verlängerten Hebelarm. Der Hebelarm ist der Abstand zwischen dem Drehpunkt des Gelenks und der Stelle, an der die Kraft auf das Bein ausgeübt wird. Wird ein Bein angehoben, muss der mittlere Servo Motor mehr Kraft aufwänden, als der äußere Servo Motor.
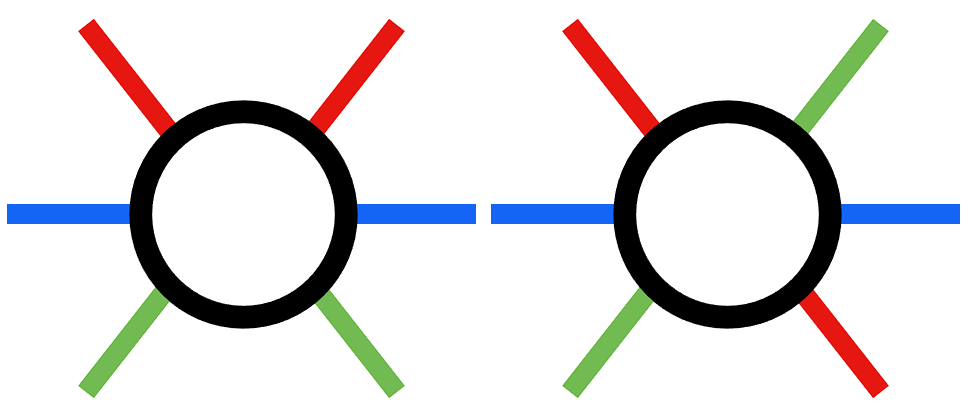
Bewegungsmuster
Um dieses potenzielle Kraftproblem zu lösen und ein effektives Gehverhalten zu ermöglichen, haben wir uns dazu entschieden, die Beinbewegungen des Hexapods paarweise abzubilden. Konkret bedeutet das, dass der vom KI-System generierte Action Space halbiert wurde, von 18 auf nunmehr 9 mögliche Aktionen. Durch diese Halbierung des Action Spaces versprechen wir uns, dass der Hexapod ein stabileres und kraftvolleres Gehverhalten entwickelt.

Beine paarweise ansteuern
Bei der paarweisen Ansteuerung, wurden 2 Arten getestet:
- Vertikale Spiegelung
- Gegenüberliegende Beine spiegeln
Coxa invertieren
Bei der Generierung des Paares muss darauf geachtet werden, dass je Paar ein Coxa invertiert ist, damit ein Schritt durchgeführt werden kann.
Schritte einschränken
Ursprünglich wurde bei jedem Lernschritt, der ausgeführt wurde, ein Aktions-Array der Länge 18 erstellt. Dadurch bewegt sich bei jedem Schritt auch jedes Gelenk. Wodurch das Lernverhalten des Hexapods beeinflusst werden kann, da einzelne Schritte nicht so einfach nachvollziehbar sind. Sticht sich z.B. der Hexapod mit nur einem Bein selbst, wird die gesamte Aktion über alle Beine schlechter bewertet.